There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study
Authors
Zichen Liu*, Changyu Chen*, Wenjun Li*, Tianyu Pang, Chao Du, Min Lin
Published on
February 07, 2025
We scrutinize the R1-Zero-like training paradigm, and share our findings in this blog.
One of the most inspiring results from DeepSeek-R1-Zero is the occurrence of “Aha moment” through pure reinforcement learning (RL). At the Aha moment, the model learns emergent skills such as self-reflection, which helps it to conduct in-context search to solve complex reasoning problems.
Within only a few days after R1-Zero’s release, several projects independently “reproduced” R1-Zero-like training on smaller scales (e.g., 1B to 7B) and all observed the Aha moment, which is typically typically accompanied by an increase in response length. We follow their settings to scrutinize the R1-Zero-like training process, and share the following findings in this blog:
1. Aha Moment Appears at Epoch 0
1.1 Experiment settings
Base models. We investigate a wide range of base model families cooked by different organizations, including Qwen-2.5, Qwen-2.5-Math, DeepSeek-Math, Rho-Math, and Llama-3.x.
Prompt templates. We directly prompt base models using the templates applied in R1-Zero and SimpleRL-Zero:
-
Template 1 (the same as in R1-Zero)
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: {Question} Assistant: -
Template 2 (the same as in SimpleRL-Zero)
<|im_start|>system\nPlease reason step by step, and put your final answer within \boxed{}.<|im_end|>\n<|im_start|>user\n{Question}<|im_end|>\n<|im_start|>assistant
Data. We collect 500 questions from the MATH training dataset, which uniformly cover all five difficulty levels and all subjects, to fill in the {Question} in the above templates.
Generation parameters. We perform a grid search for the exploration parameter (temperature) from 0.1 to 1.0 for model inference on selected questions. Top P is set to 0.9 for all experiments. We generate 8 responses for each question.
1.2 Empirical results
We first tried all combinations of models and prompt templates (Template 1 or 2), ****then select the best template for each model according to their instruction following ability and fix it for all experiments. Through a careful investigation, we have the following finding:
Qualitatively, we list all observed keywords that suggest self-reflection patterns in the following table. Note that this list may not be exhaustive. The keywords are verified by humans, and words like "wait" are filtered out because their presence may not necessarily signify self-reflection but could result from hallucinations. We note that different models display distinct keywords associated with self-reflection, which we hypothesize is affected by their pre-training data.
| Model | Best template | Observed self-reflection keywords in model responses |
|---|---|---|
| Qwen2.5-Math-1.5B, Qwen2.5-Math-8B, Qwen2.5-7B | Template 2 | rethink, recheck, try again, let's correct it and verify the steps again. |
| Microsoft-Rho-Math-7B | Template 2 | recheck, re-evaluate, check again, try again. |
| DeepSeek-Math-7B | Template 1 | let's try again, let's think again. |
| Llama-3.1-8B | Template 1 | None |
In Fig. 1a, we show the number of questions eliciting self-reflection behaviors in different base models. The results suggest that self-reflection can be observed across temperatures, with a trend that Aha moment at epoch 0 is more frequently observed with higher temperature. Fig. 1b shows the number of occurrences of different self-reflection keywords. We can observe that base models from the Qwen2.5 family are the most active in producing self-reflection behaviors, partially explaining the fact that most open R1-Zero replicates are based on Qwen2.5 models.

Fig 1a. Number of questions out of 500 MATH questions eliciting self-reflection behaviors in different base models.

Fig 1b. Number of keyword occurrences out of 40,000 responses (500 questions × 8 responses per question x 10 temperatures). y is in log scale.
After confirming that the Aha moment indeed appears at epoch 0 without any training, we wonder whether it is doing what we expect — self-reflection to correct wrong reasoning. We hence tested the example question used in SimpleRL-Zero’s blog directly on Qwen2.5-Math-7B base model. Surprisingly, we found that the base model already exhibits reasonable self-correction behavior, as shown in Fig.2.

Fig 2. We tested the same question reported in SimpleRL-Zero’s blog directly on Qwen2.5-Math-7B base model, and found that the Aha moment already appears.
2. Superficial Self-Reflection
Although the example in Fig. 2 shows great potential of base models to directly solve complex reasoning problems through self-correcting CoT, we found that not all self-reflections from base models are effective ones that lead to improved solutions. For ease of discussion, we call them superficial self-reflection as defined below.
2.1 Case studies
To identify SSRs, we conducted case studies and observed four types of self-reflection patterns in Qwen-2.5-Math-7B base model responses:
- Behavior 1: Self-reflections that double-check and confirm the correct answer (Fig. 3a).
- Behavior 2: Self-reflections that correct an initially incorrect thought (Fig. 3b & Fig. 2).
- Behavior 3: Self-reflections that introduce errors into originally correct answers (Fig. 3c).
- Behavior 4: Repetitive self-reflections that fail to produce a valid answer (Fig. 3d).
Behaviors 3 & 4 are superficial self-reflections that lead to incorrect final answers.

Fig 3a. Self-reflection double-checks the answer to ensure correctness.

Fig 3b. Self-reflection corrects an initially incorrect answer.

Fig 3c. Self-reflection that introduces an error (x=4) into originally correct answer (x=12).

Fig 3d. Repetitive self-reflections that fail to provide a valid answer (either correct or incorrect).
2.2 Base models are prone to SSRs
We next analyze the occurrences of self-reflection keywords in both correct and incorrect responses of Qwen2.5-Math-1.5B. As shown in Fig. 4, the majority of self-reflections (measured by their frequency) do not lead to correct answers across different sampling temperatures, suggesting that base models are prone to producing superficial self-reflections.

Fig 4. Number of self-reflections in correct and incorrect responses. The blue bars represent the total occurrences of self-reflection keywords in correct responses, while the red bars represent the total occurrences in incorrect responses.
3. A Closer Look at R1-Zero-like Training
While the sudden increase in model response length is often regarded as the Aha moment in R1-Zero-like training, our findings in Sec. 1 demonstrate that such moments can occur even without RL training. This raises a natural question: Why does model response length follows a distinctive pattern — decreasing in the early training phase before surging at a certain point?
To investigate this, we study R1-Zero-like training through two approaches: (1) a toy reproduction of R1-Zero on the Countdown task to analyze output length dynamics, and (2) a reproduction of R1-Zero on math problems to study the relationship between output length and self-reflection.
3.1 Length changes are part of RL dynamics
We use oat, which supports R1-Zero-like training, to RL-tune a Qwen-2.5-3B base model on the Countdown task (as used by TinyZero) using GRPO. In this task, the model is given three to four numbers, and is asked to use algorithmic operations (+,-,x,÷) to make an equation that equals to a target. This inevitably requires the model to retry different proposals, hence needing self-reflection behaviors.
The right plot of Fig. 5 shows the dynamics of reward and response length throughout the RL training. Similar to TinyZero and SimpleRL-Zero, we observe the reward keeps increasing while the length decreases first then surges, which is attributed to the Aha moment by existing works. However, we observe that retry patterns already exist in base model’s responses (Sec. 1), but many of them are superficial (Sec. 2) hence the reward is low.

Fig 5. (Left) A detailed analysis on the distribution and average length of different response groups. (Right) RL curves of test reward and model response length.
Zooming in on the initial learning period, we analyze how rule-based reward shaping affects the RL dynamics and leads to the length changes. In the left plot of Fig. 5, we categorize model responses into three distinct groups according to the rewards:
This simple decomposition reveals some insights into the RL dynamics:
- Training before step 88 is dominated by the format reward (r=0.1), which is easier to optimize by tuning the model to stop within the generation token budget and format the answer within the
<answer> </answer>block. During this period, the lengthy incorrect responses are suppressed, hence the average response length drops drastically. - At step 88, the model starts to climb the reward hill towards the higher reward (r=1 for correctness) by outputting more retries. Hence we observe a length increase in correct responses. As a side effect, the model also outputs more superficial self-reflections that are verbose, contributing to the surge of average response length.
- The overall RL process is to turn originally superficial self-reflection into effective self-reflection in order to maximize the expected reward, hence improving the reasoning ability.
3.2 Length and self-reflection may not be correlated
Following the SimpleRL-Zero setting, we train Qwen2.5-Math-1.5B with 8K MATH prompts. At the start of training, we observe a decrease in output length until approximately 1,700 gradient steps, after which the length begins to increase (Fig. 6). However, the total number of self-reflection keywords does not exhibit a monotonic relationship with output length shown in Fig. 7. This suggests that output length alone may not be a reliable indicator of the model’s self-reflection capability.
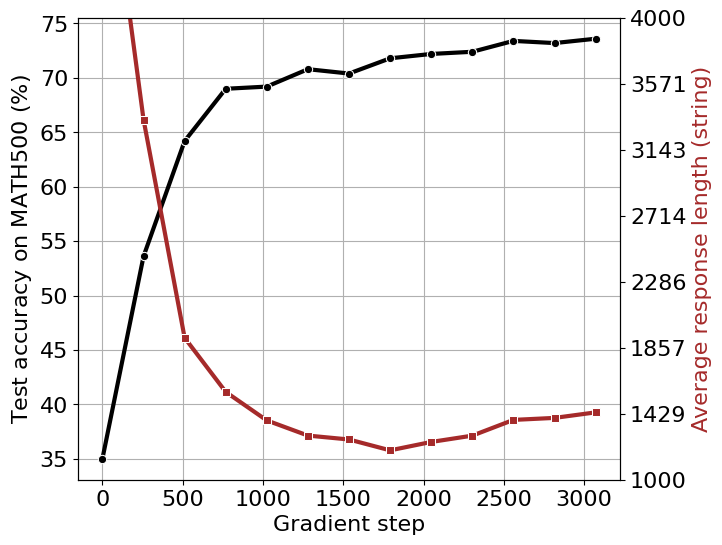
Fig 6. Training dynamics based on Qwen2.5-Math-1.5B with 8K MATH prompts. We report the test accuracy on MATH500 and average response length.
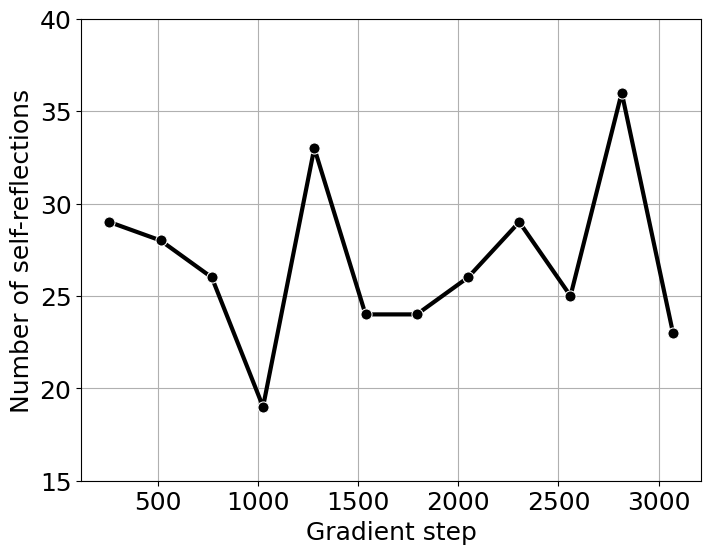
Fig 7. Total number of self-reflection keywords during training.
The full training process takes approximately 14 days on our single-node server and is currently ongoing (with progress equivalent to 48 training steps in SimpleRL-Zero). A more detailed analysis will be conducted upon completion.
Citation
If you find this blog or our codebase useful, please consider citing:
@misc{liu2025oatzero,
title={There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study},
author={Zichen Liu and Changyu Chen and Wenjun Li and Tianyu Pang and Chao Du and Min Lin},
year={2025},
howpublished={\url{https://oatllm.notion.site/oat-zero}},
note={Notion Blog},
}