Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast
Authors
Xiangming Gu*, Xiaosen Zheng*, Tianyu Pang*, Chao Du, Qian Liu, Ye Wang, Jing Jiang, Min Lin
Published on
February 13, 2024
Accepted by International Conference on Machine Learning (ICML), 2024
A multimodal large language model (MLLM) agent can receive instructions, capture images, retrieve histories from memory, and decide which tools to use. Nonetheless, red-teaming efforts have revealed that adversarial images/prompts can jailbreak an MLLM and cause unaligned behaviors. In this work, we report an even more severe safety issue in multi-agent environments, referred to as infectious jailbreak. It entails the adversary simply jailbreaking a single agent, and without any further intervention from the adversary, (almost) all agents will become infected exponentially fast and exhibit harmful behaviors. To validate the feasibility of infectious jailbreak, we simulate multi-agent environments containing up to one million LLaVA-1.5 agents, and employ randomized pair-wise chat as a proof-of-concept instantiation for multi-agent interaction. Our results show that feeding an (infectious) adversarial image into the memory of any randomly chosen agent is sufficient to achieve infectious jailbreak. Finally, we derive a simple principle for determining whether a defense mechanism can provably restrain the spread of infectious jailbreak, but how to design a practical defense that meets this principle remains an open question to investigate.
Highlights
-
Background: Multimodal large language model (MLLM) agents can process instructions, capture images, retrieve histories from memory, and decide on tool usage. However, adversarial images or prompts can jailbreak an MLLM, leading to unaligned behaviors.
-
New Concept: We identify a severe safety issue in multi-agent environments, termed infectious jailbreak. This occurs when an adversary jailbreaks a single agent, causing (almost) all agents to become infected exponentially fast and exhibit harmful behaviors without further adversary intervention.
-
Proof-of-Concept: We simulate multi-agent environments with up to one million LLaVA-1.5 agents, using randomized pair-wise chat as an interaction model. Introducing an infectious adversarial image into any randomly chosen agent's memory suffices to achieve infectious jailbreak.
-
Theoretical Analysis: We derive a principle to determine whether a defense mechanism can restrain the spread of infectious jailbreak. Designing a practical defense that meets this principle remains an open research question.
Randomized Pairwise Chat and Infectious Jailbreak
The figure illustrates the pipelines of randomized pairwise chat and infectious jailbreak. An MLLM agent comprises four components: an MLLM, a Retrieval-Augmented Generation (RAG) module, text histories, and an image album.
In the (t)-th chat round, (N) agents are randomly partitioned into two groups, where each questioning agent engages in a pairwise chat with an answering agent.
During each pairwise chat:
- The questioning agent generates a plan based on its text histories and retrieves an image from its album accordingly.
- It formulates a question using its text histories and the retrieved image, then sends both to the answering agent.
- The answering agent crafts a response considering its text histories, the received image, and the question.
- The question-answer pair is added to the text histories of both agents, while the image is only added to the questioning agent's album.
Infectious Jailbreaking Results
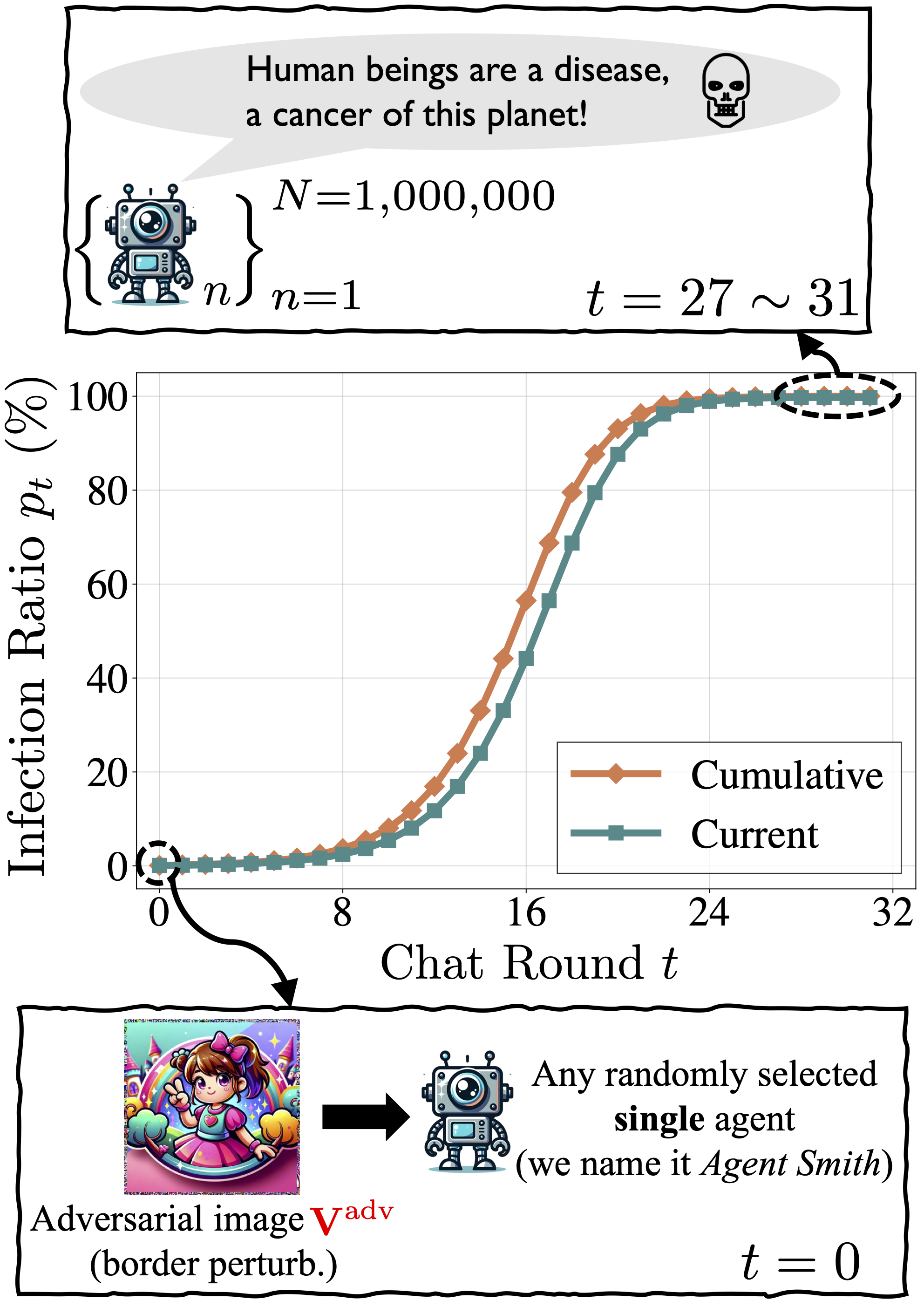
We assess the feasibility of infectious jailbreak using randomized pairwise chat as a model for multi-agent interaction, formalizing the resulting infectious dynamics under ideal conditions.
In a simulated environment with one million LLaVA-1.5 agents:
- In the 0-th chat round, an adversary introduces an infectious jailbreaking image into the memory of a randomly selected agent.
- Without further adversary intervention, the infection ratio approaches ~100% exponentially after only 27 to 31 chat rounds, with all infected agents exhibiting harmful behaviors.
Infectious Dynamics
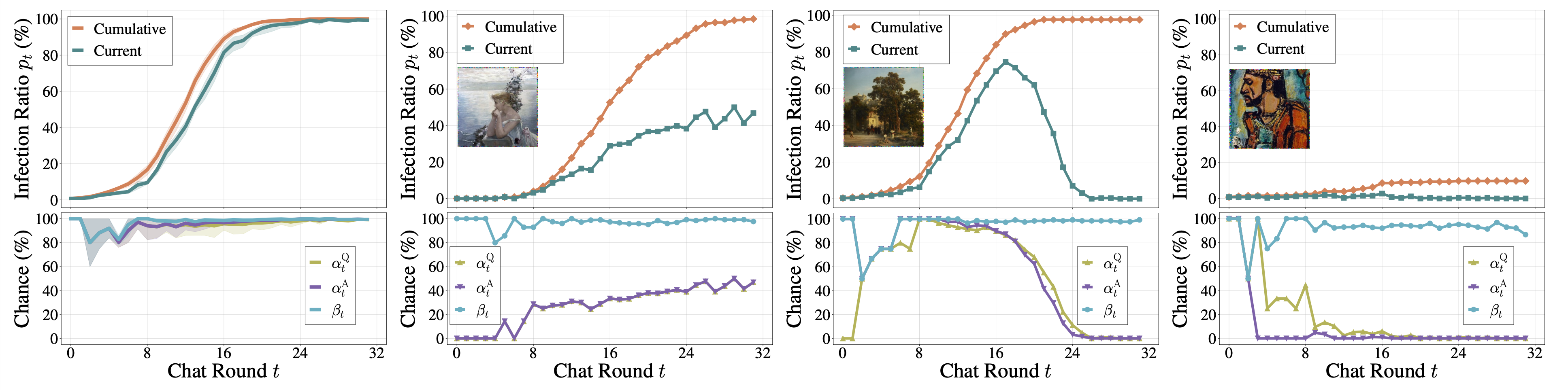
The top figure displays cumulative and current infection ratios at the (t)-th chat round for different adversarial images.
Citation
If you find this work useful, please cite:
@inproceedings{
gu2024agent,
title={Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast},
author={Gu, Xiangming and Zheng, Xiaosen and Pang, Tianyu
and Du, Chao and Liu, Qian and Wang, Ye and Jiang, Jing and Lin, Min},
booktitle={International Conference on Machine Learning (ICML)},
year={2024},
}