On Evaluating Adversarial Robustness of Large Vision-Language Models
Authors
Yunqing Zhao*, Tianyu Pang*, Chao Du, Xiao Yang, Chongxuan Li, Ngai-Man Cheung, Min Lin
Published on
May 01, 2023
Accepted by Annual Conference on Neural Information Processing Systems (NeurIPS), 2023
Large vision-language models (VLMs) such as GPT-4 have achieved unprecedented performance in response generation, especially with visual inputs, enabling more creative and adaptable interaction than large language models like ChatGPT. Nonetheless, multimodal generation exacerbates safety concerns, as adversaries may successfully evade the entire system by subtly manipulating the most vulnerable modality (e.g., vision).
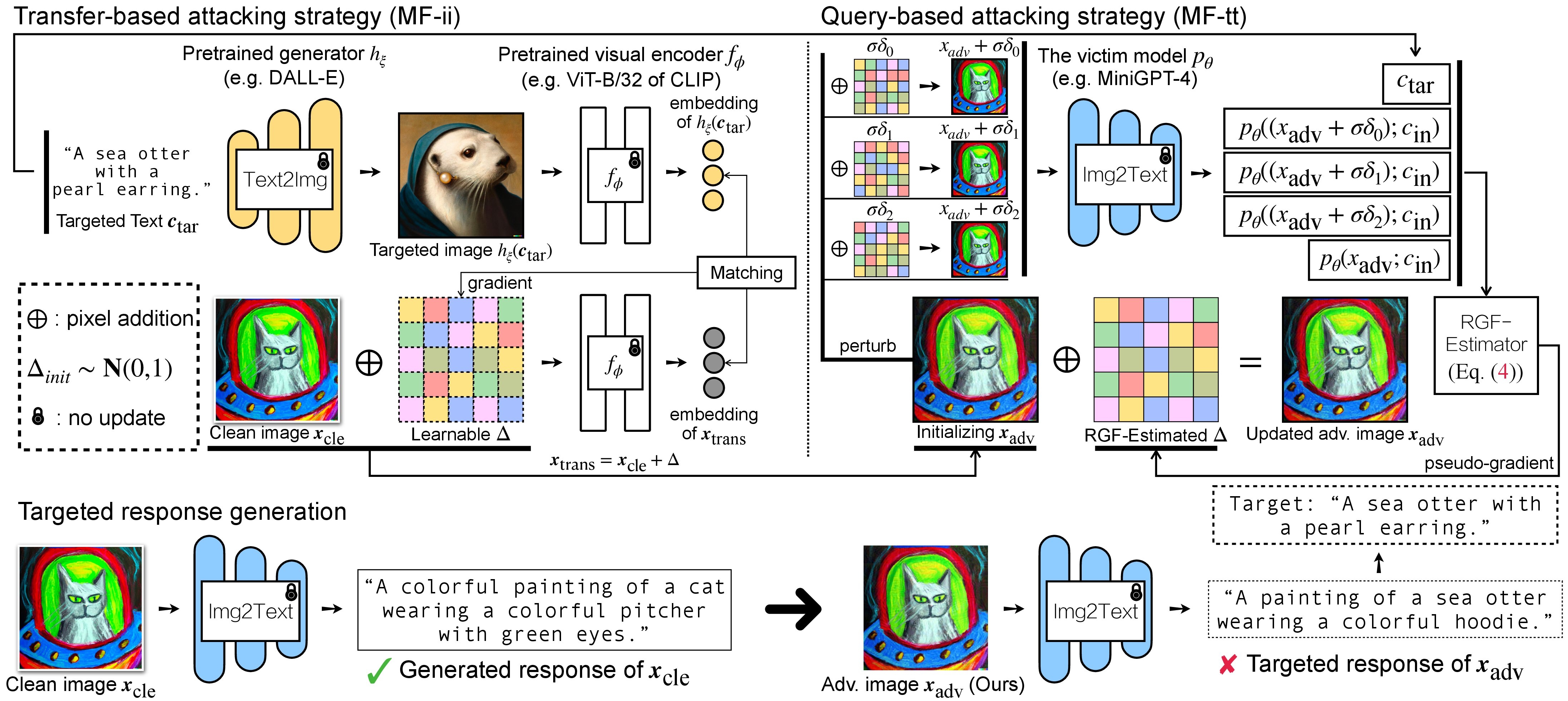
To address this, we propose evaluating the robustness of open-source large VLMs in realistic and high-risk settings, where adversaries have only black-box system access and aim to deceive the model into returning targeted responses. Specifically, we first craft targeted adversarial examples against pretrained models like CLIP and BLIP, then transfer these adversarial examples to other VLMs such as MiniGPT-4, LLaVA, UniDiffuser, BLIP-2, and Img2Prompt. Additionally, we observe that black-box queries on these VLMs can further enhance the effectiveness of targeted evasion, resulting in a surprisingly high success rate for generating targeted responses.
Our investigation provides a quantitative understanding of the adversarial vulnerability of large VLMs and calls for a more thorough examination of their potential security flaws before deployment in practice.
Overview of Proposed Method
Experiment Results
Visual Question-Answering (VQA) with MiniGPT-4
MiniGPT-4 demonstrates vision-language understanding comparable to GPT-4, performing tasks like multi-round VQA by leveraging large language models. We selected images with refined details generated by Midjourney and posed questions (e.g., "Can you tell me what is the interesting point of this image?") to MiniGPT-4. As expected, MiniGPT-4 provided intuitively reasonable descriptions. When asked follow-up questions (e.g., "But is this a common scene in normal life?"), it accurately engaged in multi-round conversation. However, when fed targeted adversarial images, MiniGPT-4 returned answers aligned with the targeted description (e.g., "A robot is playing in the field"). This adversarial effect persisted across multiple conversation rounds.

Joint Generation with UniDiffuser
Generative VLMs like UniDiffuser model the joint distribution of image-text pairs, enabling both image-to-text and text-to-image generation. Given an original text description (e.g., "An oil painting of a bridge in rains. Monet Style"), UniDiffuser's text-to-image direction generates the corresponding clean image, and its image-to-text direction recovers a text response (e.g., "A painting of a bridge at night by Monet") similar to the original description. This bidirectional process is consistent with clean images. However, when a targeted adversarial perturbation is added to a clean image, UniDiffuser's image-to-text direction returns a text (e.g., "A small white dog sitting in the grass near a stream in Autumn") that semantically resembles the predefined targeted description (e.g., "A small white dog sitting on the ground in autumn leaves"), disrupting subsequent recovery processes.
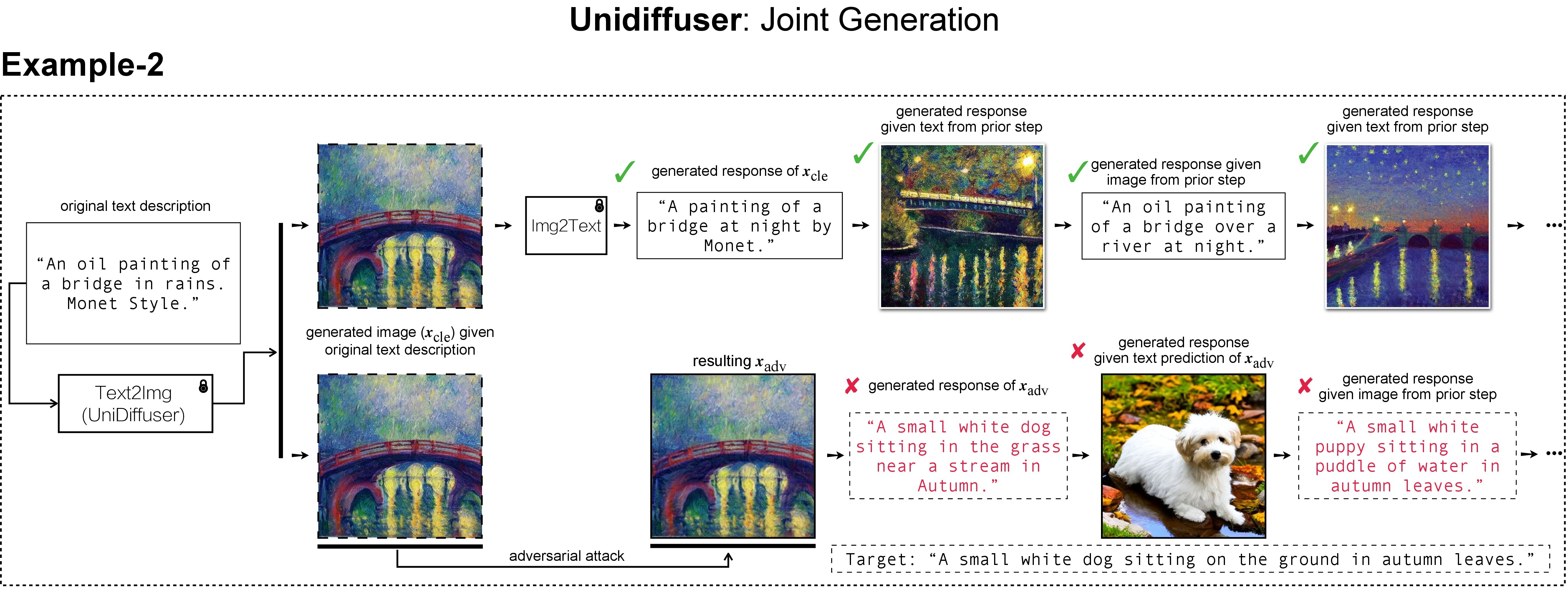
Image Captioning with BLIP-2
Given an original text description, tools like DALL-E, Midjourney, or Stable Diffusion generate corresponding clean images. BLIP-2 accurately returns captioning text (e.g., "A field with yellow flowers and a sky full of clouds") analogous to the original description or the image content. However, when the clean image is perturbed by targeted adversarial noise, the adversarial image misleads BLIP-2 to produce a caption (e.g., "A cartoon drawn on the side of an old computer") that semantically matches the predefined targeted response (e.g., "A computer from the 90s in the style of vaporwave").

Related Links
Recent works on large vision-language models include:
- LAVIS: A one-stop Library for Language-Vision Intelligence.
- MiniGPT-4 and LLaVA: Perform Vision Question-Answering on top of Large Language Models (LLMs).
- UniDiffuser: Achieves multi-modal joint generation using a single ViT.
BibTeX
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Annual Conference on Neural Information Processing Systems (NeurIPS)},
year={2023}
}